The power of LLMs in software development
Since the release of GPT models, I’ve been keeping an eye on what was going on with them, and what good use can be done.
When GPT-3 was released, I worked on a product called Write it for me that helped makers write publications based on given needs. You could tweak the result by selecting a tone, a language, etc. The target was product makers — I know the pain of doing marketing. Having the power to delegate content writing to AI for SEO was a good use.
Funny enough, ChatGPT was unveiled and took over the world a few months later. Innovation outpaced my shipping velocity.
I’ve never been a huge fan of LLMs, mainly because I find them overrated. Headlines play with fears by convincing people their jobs are going to be outdated shortly, but this is misleading. LLMs are bringing a groundbreaking new paradigm and it can’t be ignored. Still, they fail on most value-added tasks.
I’m not against “AI”, ML, or LLMs. I’m cautious about them. We see the benefits, but we must not ignore shortcomings. I wanted to experiment and try them in software engineering to solve real-world problems.
When words solve more than algorithm
Sometimes, it’s easier to explain what we try to achieve with words rather than transcribing it with code.
Last week, I had to do scraping: gathering and clearing a dataset. My goal was to extract email addresses from a list of profiles by reading their PDF resume one by one and extracting the email from a string.
The first thing you may think of is RegExp. That’s the strategy I used for the first round. The thing with PDF is that reading its content from a browser is not always easy. The email is located in the string with noisy text around. Instead of having whitespace before and after the mail to delimit it, we end up with misplaced whitespace. RegExp is helpful in shortening a text range to where the email is, with an acceptable 32 characters around so we don’t cut it in half.
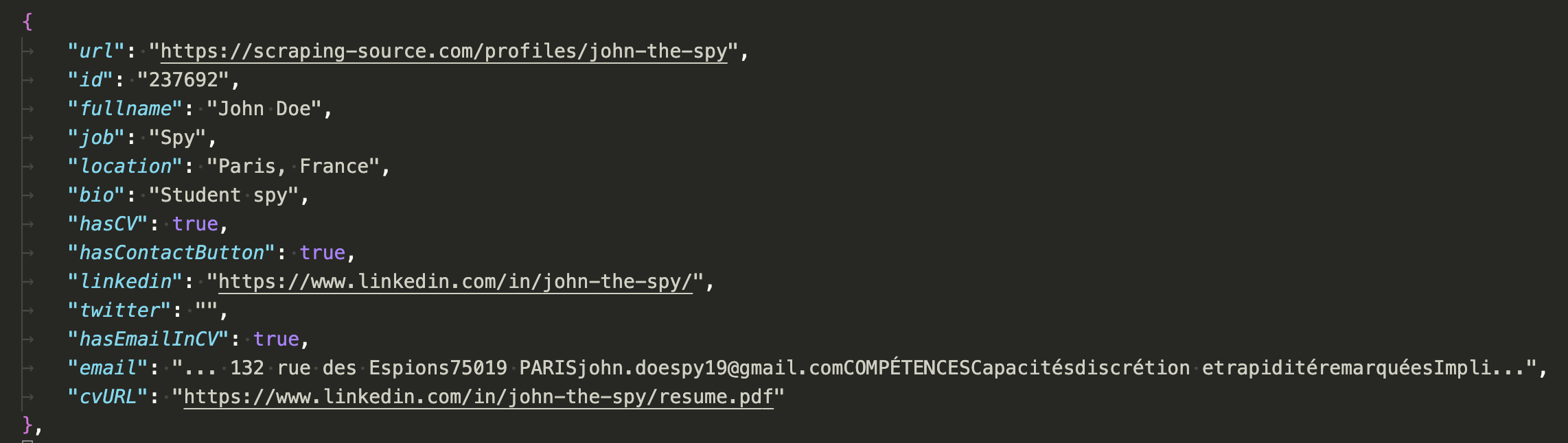 Scraped data that must still be cleaned up
Scraped data that must still be cleaned up
Based on the screenshot above, your brain is smart enough to guess what the email of our dear John the Spy is, right? But how would you translate it into computer instructions?
This is where an LLM enters. I thought “if I explain it with words, and given that LLMs are trained on the public Internet, it might understand and cross-reference with its training dataset”.
To validate my hypothesis, I tried a few samples using ChatGPT and got 100% success without any hallucinations. God, does it mean GPT has been learning from the website I’m scraping?
Implementation
Now that the hypothesis is validated, we must industrialize the process. Instead of paying for OpenAI’s API (maker bias on how to spend less), I gave a chance to Ollama to have a local-running LLM, using the Llama 3 model.
I tried to write an explicit prompt to get a clear answer, despite not being a skilled prompt engineer. The instructions:
Reply with the JSON object only, so your response can be used in an API. With the following JSON object, take the “email” property, clean the email address, and save it in a new “clearedEmail” property. {profileJSONObject}
Thanks to the Ollama Node.js library, industrializing the data cleaning could be done in a breeze.
Integrating the LLM was as simple as that. The story could end up here, but I’ll dig into implementation issues.
The first thing is that Llama wasn’t responding in a JSON-only format, but always prepending text like “Here’s the object with the email cleared” (and other variants).
I had to clean the response string to extract JSON. Not a big deal, as I was inputting a flat object and expected to get a flat object in response too.
I looked for the index of { to go directly to the JSON-stringified object, and the index of } to get its end. This substring would clear any noise in the response.
Once the substring was isolated, it could easily be parsed and manipulated in JavaScript.
While we could have thought of it at first, I hadn’t predicted that the response object would not always have the same structure. Sometimes returning the full input object with a new clearedEmail property, sometimes altering the email property. Or even answering with a new object containing the clearedEmail property only.
These various behaviors add up to the blackbox of obfuscated and undebuggable dependency we’re adding to the project.
Mitigating hallucinations
We’re getting close to a working data extraction and formatting project. What could go wrong now?
Are you curious? Have you looked into the extracted email address?
Yes, doe.john@gmail.com looks like a valid email — a coherent one given the object we inputted to Llama. But… if the email is the one we’re looking for, it might also be in the email property, right?
Out of curiosity, let’s try adding watchdogs. Once the response is parsed and the email extracted, let’s match it against the original string. If it’s OK, then we have a high confidence rate that the email is correct. Any other case must be flagged as a failure to either retry or do manual processing.
Out of a total of 700 datapoints, 370 had an email and 125 failed to be cleaned.
Failure does not mean the LLM hasn’t found any email but rather has given a wrong answer and had to be reprocessed (either automatically or manually — I went with the latter).
A ~30% failure rate is acceptable in this situation, given the time saved cleaning over 300 datapoints.
Note that in this experimentation, I didn’t mention false-positives where PARISjohn.doespy19@gmail.com would also have been detected as a valid email. I encountered only one datapoint in this situation.
Now what?
This was my first interaction with an alien Llama and a concrete usage of it.
My skepticism is not as high as it was a few months ago. We’re only at the beginning of this technology, and given its progress, it will become a great copilot for every boring task we all have in our jobs. But it’s not going to remove jobs. Any company doing so is missing its purpose. Jobs are getting enhanced and transformed — removing boring and time-consuming tasks to focus on value-added ones.
In production-grade apps, LLMs are not yet ready to take the big leap. A 30% failure rate (aka 70% success) is a very good score, but it’s still very high and hard to mitigate or make predictable when running at large scale.
In one word, LLMs are copilot. Like dogs are humans’ best friend, LLMs are becoming humans’ best copilot in their job.